如何将fishbot小车变为更加智能的小车,现在最想实现的是语音交互和指令执行,望大佬们指点指点思路和方向。
-
看起来你正在寻找一个能够将语音控制与ROS2(Robot Operating System 2)结合的方案,以实现流畅的人机交互和基本的移动功能。以下是对你提到的方案的分析以及可能的建议:
-
ESP32S3接入百度文言一心大模型:
- 优势:百度文言一心大模型是百度开发的先进语言模型,可以提供高质量的语音识别和文本生成功能。
- 劣势:独立于ROS2意味着你可能需要编写额外的代码来将两者集成,这可能会增加项目的复杂性和开发时间。
- 建议:如果价格合适,并且你愿意投入一些时间来学习和解决集成问题,这可能是一个可行的选择。你可以考虑先实现一个原型,看看是否满足你的需求。
-
ESP32S3接入科大讯飞语音:
- 优势:科大讯飞是中国领先的语音识别和合成技术提供商,其技术成熟且易于集成。
- 劣势:同样,如果与ROS2的集成不够直接,可能需要额外的开发工作。
- 建议:你可以考虑查看科大讯飞的文档和API,看看是否有直接支持ROS2的库或示例代码。如果没有,你可能需要评估集成的复杂性和成本。
-
ROS2直接接入语音库:
- 优势:如果语音库与ROS2兼容,那么集成可能会更加直接和简单。
- 劣势:实现流畅交流可能是一个挑战,因为许多现有的语音库可能无法提供与先进语言模型相同级别的自然语言处理能力。
- 建议:你可以考虑使用一些开源的语音识别和合成库,如PocketSphinx或espeak,但这些可能无法提供你所需的流畅交流能力。如果你对ROS2和语音处理都有深入的了解,你可以尝试自己开发或修改这些库以满足你的需求。
可能的建议方案:
-
结合ESP32S3和ROS2:你可以考虑使用ESP32S3作为语音输入和输出的前端设备,负责语音识别和合成。然后,你可以通过某种通信协议(如Wi-Fi、蓝牙或串口)将ESP32S3与ROS2节点连接起来。在ROS2节点中,你可以处理语音指令,控制机器人的移动和其他功能。
-
使用云服务:另一个可能的解决方案是使用云服务进行语音识别和文本生成。你可以将语音数据发送到云端,然后接收处理后的指令或文本。这种方法可以利用云端的强大计算能力,但可能会受到网络延迟和带宽限制的影响。
-
寻找现成的解决方案:你也可以考虑寻找一些已经集成了语音处理和ROS2的现成解决方案或开源项目。这些项目可能已经解决了许多你正在面临的问题,并且可以为你提供一个良好的起点。
最后,无论你选择哪种方案,都需要确保它能够提供你所需的流畅交流和基本的移动功能。同时,你也需要考虑成本、开发时间和项目的可持续性。希望这些建议能对你有所帮助!
以上为生成回答,仅供参考~
-
-
现在还没有大佬提供具体方案,但是我在CSDN博客上看到一位大佬讲述了ros2接入科大讯飞的SDK然后实现了语音+键盘控制fishbot完成了5个语音命令,也算是跑了一下语音控制的流程。但使用过程中发现语音识别特别慢和不准确,而且过程也较繁琐看来还不是最好方案。不过挺好的,至少说明白了语音控制并不是机器人听到了语音就开始执行了。以后将持续更新此贴作为交互的学习。
-
插眼,有时间也希望搞个智能机器人
-
@2438413171 哇塞,大佬我们又相见了,太兴奋了,又来我帖子了,先给大佬汇报下最近进展:
1、上次科大讯飞+键盘控制的方案最终放弃了;采用了新的方案,用vosk库替代了科大讯飞,用navigation2替代了键盘控制。
2、已用vosk库实现了语音识别,感觉与科大讯飞差不太多,也不是很准确。
3、然后使用espeakng库将文字合成语音播报。
4、利用API链接coze智能体将vosk识别的语音传过去,然后接收到反馈的内容已实现。
5、利用rviz2提前将目标点的坐标记录下来写入xml文件中,然后使用指令映射的方式写入navigation2的目标接收节点中,已实现导航。由于横跨太多内容,现在以上步骤都是单步单一功能实现的,接下来就是要把以上步骤完整的串起来,先完成既定导航目标的实现。现在唯一一个还没有确定的就是如何告诉navigation2初始位置。我在听小鱼老师的课时感觉这个还是有点难,所以这步先留着等我把上面单步实现的串联起来后再来解决这个问题。
再次感谢大佬上次的指点及本次的光顾,感谢!
也再次感谢小鱼老师免费的教学,随着学习的深入我才越来越体会小鱼老师的苦口婆心,不要复制粘贴代码不然看完视频没感觉,实际上根本没学进去。只有在自己继续深挖的过程中才会发现这些基础知识的重要性! -
@onedream 看了贴子有点遇到知音感觉,我也有此想法,我是想着后面语音控制小车能实现像现在电车那样在复杂路况上的模拟,除了语音转换感觉最难的是识别意图然后去执行对应的控制器;不知道能不能做到那种程度。越学习感觉学的东西还有很多,一起加油!
-
@jarvis 是的,思路上应该大差不差,我的终极目标也是将聊天和控制结合,就会走到你说的意识识别。这一步对我来说还是很遥远,不过现在技术发展很快,先把基础的打通,经验先积累着,说不定哪天就可以实现了啦!哈哈。
-
@onedream 经过一个多月的实践与学习,不停的改不停的改,总算是成功了。这期间做了以下优化:
1、将初始位置固定,并在启动nav2时自动实现初始位置。
2、成功将3个模块串联起来,vosk识别的语言通过发布者将内容传递给coze,然后收到coze消息后通过发布者传递给导航。美中不足的就是:
1、vosk识别非常不准确,而且每次都会不知道什么时候说话的结束。但是程序运行久了,我发现识别准确度会提高,这是什么情况啦?
2、为了实现以上功能我打开了5个终端同时运行,不知道能否实现一个终端实现以上流程。本想上传视频结果发现不能,那我就上传图片吧
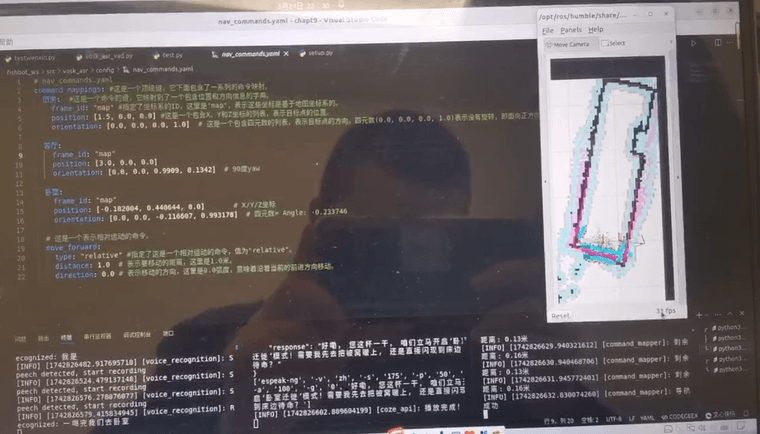
-
@小鱼 对了,小鱼老师,我请教下,我想在fishbot小车上装上麦克风阵列用于接收语音消息。这个是随便在淘宝上买个就可以实现吗?还是要基于你开发的主控板来有针对性的选择麦克风阵列啦?还需要增加其他主控版吗?恳请有空时指导下,谢谢小鱼老师。
-
@onedream launch文件研究一下。把node启动都放到一个lanuch文件里就可以了。
-
@onedream 随便一个即可
-
@499391260 要的,谢谢大佬指点。
-
@小鱼 好的,谢谢小鱼老师。
-
@onedream 又经过一个多月的思考和研究,语音识别问题总算找到了我非常满意的解决方案。学习了开源小智AI的IOT功能,打算把他和fishbot结合起来。将IOT控制板块通过mqtt协议传入ros2话题中这样就完美的解决了语音识别不准的问题。但是现在基本调通了。还没有进行大汇总,如果后续能够完全调通,那我的这个智能小车就基本实现了我想要的功能了。哈哈,后续就是对fishbot进行2驱变4驱的改变了。因为万向轮无法适应任一有阶梯的环境。
-
@onedream 经过4个月零2天的时间,我成功实现了将fishbot变成智能语音控制导航的小车了,说去哪里就去哪里。但仍有些不足:
1、无法完成相对目标点前进;
2、现在导航采用的坐标点映射,并不能像网上那种自我标定,自我导航;
3、mqtt运行还不稳定,多次收发后会导致程序崩溃,我在想是不是我没有自建服务器的原因,现在采用的是公共服务器。
不过总体的链路已经完成了,接下来就是查漏补缺的时间了,期待能做个室内室外都能跑的机器人,哈哈!