ROS2 Humble CPU占用率比Foxy高
-
@rty813 感觉问题出在 dds上,个人觉得 fastdds 要比 cyclonedds 本地通信更好些
-
@小鱼 我用FastDDS也做过测试,CPU占用率Humble依然比Foxy高。
用Humble的主要原因是,我这个是arm64平台(Nvidia jetson),操作系统是ubuntu18.04,通过编译安装的Ros,使用fastdds的时候发现,脚本长时间运行以后,会出现发不出来消息的情况。也就是没有任何报错,但是就是没有任何消息发出了。通过脚本订阅也收不到,通过ros2 topic echo也看不到,因此换用了cyclonedds。这个不是重点。 -
这是我在一个armv7架构的ubuntu20.04中测试的结果,用的是fastdds。可以看到,此时差异更加明显,humble的CPU占用率高出foxy两倍。我很怀疑是rclpy库的问题。
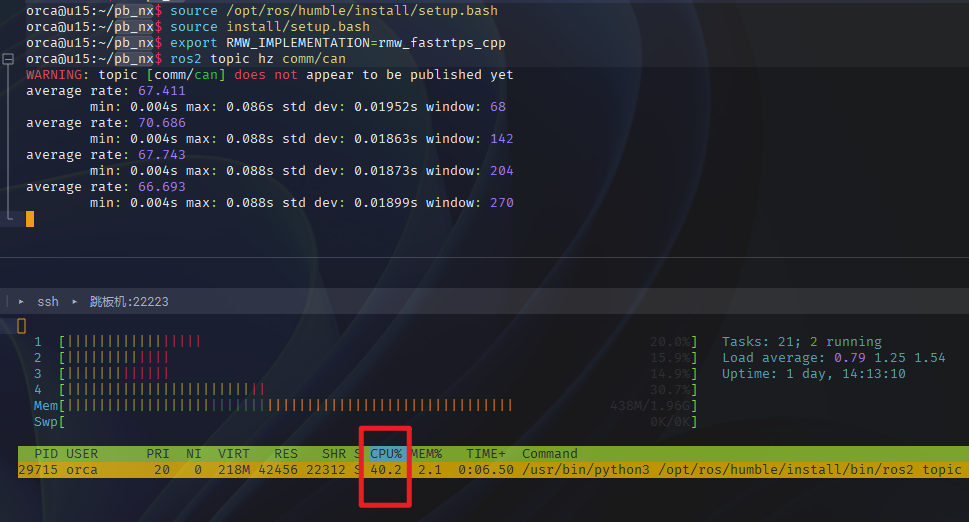
-
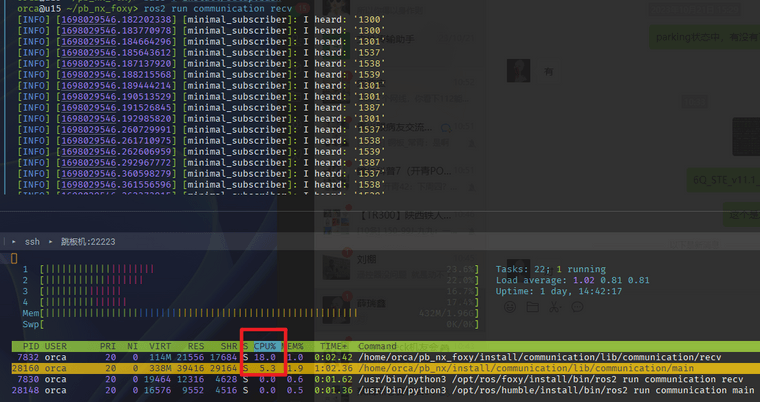
我用C++来接收的话,CPU占用率就基本上没有什么变化,甚至Humble更低一点。所以更怀疑是rclpy的问题。
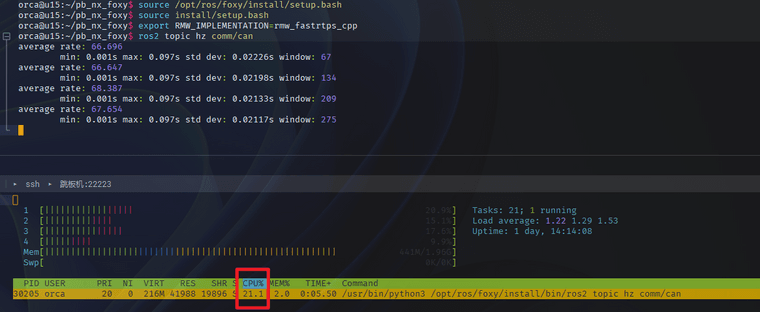
ros2 topic hz应该也是用python实现的。Humble:

Foxy:
-
@rty813 在 ROS2 Humble CPU占用率比Foxy高 中说:
ros2 topic hz应该也是用python实现的
这个是 python 实现的,我还特意去翻了下 foxy 和 humble 版本的 ros2 topic hz 的源码,并没有什么区别,可能是更底层以一步的封装问题。
@rty813 在 ROS2 Humble CPU占用率比Foxy高 中说:
使用fastdds的时候发现,脚本长时间运行以后,会出现发不出来消息的情况。也就是没有任何报错,但是就是没有任何消息发出了
如果只用C++可以尝试仅共享内存的中间件,比如:https://github.com/ros2/rmw_iceoryx
-
@小鱼 非常感谢。我去github上再问问吧。
至于rmw_iceoryx,我记得python好像也可以吧?这个只能用C++吗?而且这个库我记得有个问题,就是如果想和其他中间件通信的话,就必须要用到一个gateway来转换,这个我们目前的场景不太适合,我们是多台机器之间需要进行通信 -
@rty813 python支持不太行,要效率还是用C++,也可以用FASTDDS实现进程间通信,提高效率
-
这个问题应该是dds的问题,默认是FastRTP dds,这个不支持带宽高的数据通信,改用cyclonedds会改善很多。
-
@3023304527 有损网络 fastdds 表现会比 cyclonedds,localsocket 也会 出现吗,有尝试调节下面两个参数 吗
解决方案: 减小
ipfrag_time参数的值。net.ipv4.ipfrag_time / /proc/sys/net/ipv4/ipfrag_time(默认值为30秒):保留IP片段在内存中的时间(以秒为单位)。通过运行以下命令将该值减小到3秒,例如:
sudo sysctl net.ipv4.ipfrag_time=3
减小此参数的值也会减少未接收到片段的时间窗口。该参数对所有传入的片段是全局的,因此需要考虑在每个环境中减小其值的可行性。解决方案: 增加
ipfrag_high_thresh参数的值。net.ipv4.ipfrag_high_thresh / /proc/sys/net/ipv4/ipfrag_high_thresh(默认值:262144字节):用于重新组装IP片段的最大内存使用量。通过运行以下命令,将值增加到128MB:
sudo sysctl net.ipv4.ipfrag_high_thresh=134217728 # (128 MB)
显著增加此参数的值是为了确保缓冲区永远不会完全填满。然而,假设每个UDP数据包都缺少一个片段,在ipfrag_time时间窗口内接收到的所有数据可能需要相当高的值来保存。 -
@3023304527 和DDS无关。两个DDS我都测过,在我这种数据量的情况下,CPU占用情况没什么区别。
-
@小鱼 我后来去rclpy仓库提了issue,经过排查发现,humble的
spin_once->add_node()中的__gc.trigger()耗时比foxy高。然后,ros2 topic hz命令的源码实际上是在循环调用spin_once,而不是spin函数,就会导致trigger函数频繁调用,进而导致Humble的ros2 topic hz命令的CPU占用高。然后我又进行了测试,我用官方demo改了改,用spin()函数,避免频繁调用trigger。经过测试,在Jetson NX(arm64)上,CPU占用率Foxy和Humble基本持平了。但是,我又在armv7平台进行了测试,发现及其离谱,100Hz的频率收发数据,Humble达到了70%的CPU占用,而foxy仅30%左右。这个目前就没有思路了。
-
@rty813 大概了解了整个过程,比较好奇是否确认就是 rclpy 库造成的,但感觉大概率是 rclpy 问题,可以测试使用 rclcpp 在 ARMv7 平台上是否可以达到同样性能,这样可以排除是更底层的原因影响造成。
另外就是考虑到系统调度角度,如果资源出现竞争,往往会导致性能下降非常迅速,ARMv7 平台上的 humble 和 foxy 版本性能差异如此明显,可能就是这样造成的,可以测试 20hz 或者更低的频率两者的表现是否相当。
-
@小鱼 测试了一下:
C++情况下,差异不太大,100Hz频率下foxy 16%,humble 20%python:
40% foxy 100Hz
85% humble 100Hz20% foxy 50Hz
51% humble 50Hz8% foxy 20Hz
20% humble 20Hz感觉还是rclpy的问题比较大